|
Банки и базы данных |
|
Тема 10.Распределение базы данных |
назад | оглавление | вперёд |
Все таблицы данных распределяются
по сети (узлом), где осуществляется их применение. Каналы между узлами – соединения.
Все таблицы данных
распределяются по сети (узлом), где осуществляется их применение. Каналы между
узлами – соединения.Все
данные в сети делятся на 2 подвида:
Преимущество:
Недостатки:
Все распределенные базы данных делятся на два типа:
Все узлы в распределенных БД являются автономными, т.е. полная независимость узла от других узлов.
Задачи РСУБД:
Каждая таблица имеет: имя, состоящее из:
Существует оператор, который позволяет отправить таблицу на любой из узлов сети: MYGRATE TABLE эту таблицу можно найти по локальному каталогу в котором эта таблица была размещена после создания. Когда запрос обращается к таблице, считывается имя и затем считывается адрес, где находится.
Порядок выполнения запросов в БД
Узел, из которого исходит запрос, называется главным. Узлы, из которых исходит запрос, называется дополнительными.
Архитектура РСУБД

Транзакция в РБД может состоять
из нескольких мастей – агентов.
Транзакции состоящая
из нескольких агентов называются глобальными.
Транзакция, с которой
начинается обработка, называется инициирующая.
ДТ – диспетчер
транзакции. Фиксирует начало и конец транзакции, передает информацию о четности
планировщику.
Планировщик
– составляет расписание работы транзакции, устанавливает блокировку по
чтению БД.
ДД – диспетчер
данных. Выполняет команду чтения и записи над данными, результаты этих операций
передаю планировщику. Планировщик передает ДТ, а ДТ передает обратно транзакции.
Протокол двухфазной фиксации
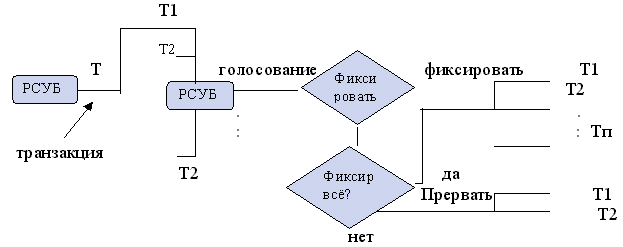
Главная транзакция посылает
команду подтранзакции, фиксировать или прервать. Если голосование единогласно,
то принимается решение фиксировать и эта команда отправляется подтранзакциям.
Если же хотя бы одна подтранзакция обработала с ошибкой, то главная подтранзакция
посылает подтранзакциям команду отказ и все данные уничтожаются.
Фрагментация –
хранение фрагментов таблицы в разных узлах сети.
Пример:
|
Категория билетов |
Станция |
цена |
|
|
|
Красноярск |
|
|
|
Новосибирск |
|||
|
Москва |
|||
|
Владивосток |
Горизонтальная фрагментация таблицы
Разбиение таблицы на фрагменты
по строкам выполняется с помощью команды R:=(R(SELECT * FROMR WHERE Город =
“Новосибирск”))
Вертикальная фрагментация
– разделение таблицы по вертикали (убираются те данные, которые не нужны).
Стратегия распределения нефрагментированных файлов.
Чтобы
оптимально распределить файлы по сети, нужно. минимизировать количество удаленных
обращений и максимизировать число локальных обращений.
Алгоритм размещения
файла по сети
Cij – объем свободного
дискового пространства узла j;
Fi – размер файла i;
Тк – транзакция
N - число
узлов
Определяется значение каждой транзакции к каждому файлу Fik.
|
Ф Т |
1 |
2 |
3 |
|
1 |
10 |
0 |
0 |
|
2 |
0 |
10 |
30 |
|
3 |
5 |
10 |
0 |
Среднее число запусков транзакций на узлах сети. Nij
|
У Т |
1 |
2 |
|
1 |
2 |
1 |
|
2 |
0 |
2 |
|
3 |
2 |
0 |
![]() Вычисляется
весовой коэффициент Vij, определяется на какое место нужно отправить файл.
Вычисляется
весовой коэффициент Vij, определяется на какое место нужно отправить файл.
|
Ф У |
1 |
2 |
3 |
|
1 |
30 |
30 |
0 |
|
2 |
20 |
20 |
60 |
максимум (Vij) для указанного узла j.
Осуществляется проверка:
![]()
Как только файл нашел свой узел, все соответствующие столбцы удаляются из таблицы. Как только свободное дисковое пространство на узле заполнилось, то соответствующие ему строка и столбцы удаляются из таблицы. Таким образом распределяется от файла к узлу.
назад | оглавление | вперёд